So there's different estimates, but people estimate that Amazon has between 150,000 and 450,000 servers that are backing its public cloud that you can get access to. Similarly, there are estimates that Google and Microsoft have over a million different servers that are backing their infrastructure that they use to support things like Gmail, or Google search or Bing search.
So cloud services have become really a fundamental capability that you need to be able to build really large scale and compelling applications, like Amazon and Google and Microsoft do, or the many start-ups that are doing really fascinating things.
Now there's lots of material on building web based services. using protocols like the Hypertext Transfer Protocol, or HTTP. So what do we need if we're going to talk to a server that's sitting remote from our mobile device?
So we've got our mobile device that's sitting here, and we're going to communicate between it and some cloud resources. So what do we need to do in order to support that interaction? Well, one of the most important things we have to do is we have to select a protocol for talking to that cloud. How do we go in about and talk to the cloud, the cloud, and that's what a protocol is.
A protocol is a set of rules dictating how we communicate with the resources on the other end of this network. Now why do we need a protocol, or some specialized way of communicating, and what does the
protocol get us? So if we just go and make a local method call, this is going to be, you know, very fast, nearly instantaneous.
But when we go and do some communication over the network, for example, we communicate over a cellular connection to resources that are sitting in a cloud that could be, you know, thousands of miles away, this could be milliseconds to seconds to do that communication. So there's a substantial longer period of time to establish that connection to transfer data and to receive some type of response that we're waiting for. So a big question that comes up is, well, how long is too long? When should I disconnect from that server and assume that my communication from my mobile device failed?
because, we've all experienced it, where you're driving along and suddenly your call drops because your signal goes away. Well how does that cloud know when it's been too long since it's heard something from you? Or, what if you go and log in to a website, when should it, decide to De-authenticate you and make you log in again? All of these things are aspects of the protocols that we design in order to communicate with some other entity that's farther away. And it's really important to have a robust protocol for this communication to ensure that we interact securely and reliably and quickly with the resources that we're trying to interact with.
So to give you an example, think about the Mars Rover that, that NASA has launched and been controlling from the earth. When they send a message from Earth to the Mars Rover to drive it or control it, it can take a substantial period of time for that message to receive, to be received on Mars by that rover. It's not milliseconds or seconds on the, it's on the order of hours. So think about it, you're driving this rover, and suddenly it hasn't received a message in an hour. What should it do? How should it respond? Should it keep going at 50 miles an hour or 10 miles an hour or however fast the rover goes, or should it stop? Should it try to return to where it started from?
So this is what a protocol defines, is it tells you how you communicate with another entity. And it defines a syntax, or basically a format, for the messages that you can send to that other entity. So it says, when I send a message, it has to have these properties to it, and that's the syntax. It defines semantics, and this is basically the meaning of the messages. So if I send you message A and then I send you message B, here's what I mean by that, I don't want you to get confused, I want you to understand the semantics of my messages, or the meaning of them. And then it spells out the timing, so I if I send you message A, how long do I have before I should send you message B? Or should I even send you message B at all? Should I send you something else instead? So building and selecting the right protocol for the interaction with the cloud is one of the most important aspects of mobile to cloud interactions.
So how do we talk to 150,000 servers in Amazon EC2? How does a lonely little mobile device, that's connected to some network, out in the wild. Get access to these thousands of servers, that are sitting in some cloud computing environment. So how do we get from there to there? Well the way that we're going to talk about getting from the mobile device to the cloud is through the use of HTTP. And what you can think of HTTP is, it's basically a dialog or a language that a mobile device can use to speak to a cloud, it's a protocol, an application protocol, for communicating between devices on a network.
Now. We're going to use HTTP here as our protocol for communication. But it's helpful to have a little bit of
history. And understand what HTTP, was originally built for. HTTP is the protocol, or the way that your browser communicates with a web server. In order to retrieve resources from that web server such as a web page.
So when you go and you log in to Facebook, for example, your browser is sending HTTP, probably a series of HTTP requests, to one or more Facebook servers. And then that server, or servers that are receiving the request or requests. Send data back to your browser. HTTP is a client-server protocol and what that means
is that, the interactions that are mediated via the HTTP protocol, are always initiated by a client that wants to.
Access or request, some resource on the server.
So the server has a series of resources, that it can provide to the client, and the client sends requests for those resources and the server. Returns responses to those requests. And the responses may have the resource that was requested or it may have a message indicating why the Server could or couldn't process the request, that the client sent.
But fundamentally, the HTTP protocol is an application protocol that is client-server. So, the client will always be initiating the communications. And there are some changes to this with newer things like web sockets. But in general, the client will always start the interaction. And the server will receive the interactions. And process them. So, this is the fundamental way, that HTTP works.
Now the client can be either a mobile device as we'll focus on in this class, or it can be a browser. So, we can have a mobile device be the client, or we can have a browser be the client. Or we could have some other device, maybe in the internet of things, we use HTTP as the protocol to communicate between different pieces of equipment in a factory and the different controllers, that are monitoring their status. So HTTP is a general purpose protocol. That can be used, to communicate between a client and a server.
Now one of the reasons that HTTP has become so popular for mobile integration with cloud, is that HTTP is a widely used protocol already. All of the websites that you visit are already using. HTTP as the protocol that's being used to access those web res, resources. So there's already so much infrastructure that's been built up and so much investment that has been put into HTTP protocol, and so much understanding of how the HTTP protocol works, that organizations naturally want to reuse. That infrastructure and investment, on their mobile platforms. So by using HTTP, they can write a server side, that provides access to these resources, which could be a service, or could be a web page. And, they can provide a common interface
to those resources, through HTTP.
It's a common protocol and a common server site interface, to access those resources. So when a server sends a response back, it doesn't necessarily have to care whether the person or thing that's consuming that response is a mobile device or a browser, or some other thing that it's never seen before. As long as that thing knows how to speak the HTTP protocol, it can consume the resources and services, that are available on that server.
So why are we using a web browser protocol to integrate mobile clients with cloud services? Why do we want to use HTTP to talk to the cloud? Well HTTP provides us a number of nice properties. One is, we've got a uniform interface that we can provide via HTTP to the services or resources that are sitting on the server. And, for example, if a client is a Browser and sends a request over HTTP and that Server rec, receives that request, the request is exactly the same as if a mobile device had sent it.
So, if this is a Mobile device that's sending that request, either way on the other side, on the server side, that request still has to conform to the same requirements and specifications of the HTTP protocol. So we can have a common interface. This is one of the big advantages of using HTTP to interact with cloud resources and services.
Is we don't have to go and rewrite everything from scratch and figure out a whole new way of having our servers accessible and having mobile devices able to communicate with them. We can reuse what we're already building and providing to our browser based clients and the web is ubiquitous. Everybody's building websites, everybody's supporting web service as it is.Why not reuse this infrastructure for mobile? And so that's one of the big reasons behind using HTTP to support mobile and cloud interactions.
Now, we get a number or of other great things as well. There's already all kinds of stuff on the server side from a framework and programmatic perspective that we can use to process HTTP requests. So there's things for doing stuff like sessions or remembering when people request something, who that person is and what they previously requested or what other data is associated with their current login.
We also get things like Data marshaling. This is very important when you want to convert from the format of the HTTP request to some other format that you need to process. And there's a huge amount of infrastructure that's already been developed, in terms of libraries and frameworks, that you can use to program if you use HTTP as your underlying protocol for your interaction with the cloud.
But there's also a number of other reasons that it's really nice to use HTTP. There's also infrastructure that decides, how do we load balance and distribute requests across our servers? So for example, if you have a million people accessing your service simultaneously, how are you going to distribute those requests across those servers? So, Load Balancing infrastructure for HTTP can be reused if we're using HTTP as the communication mechanism with the cloud. So there's such a significant investment both in the existing frameworks and libraries, the load balancing and other management infrastructure that's been developed for HTTP. It's natural to use HTTP as an interaction mechanism with the cloud.
Now, there's some challenges to using HTTP, particularly when things that we would like to do with our mobile services don't fit into the client server model where the client is always the mobile device requesting some resource from the server. So maybe an email comes into the server and your client needs to be notified about it. Well that's difficult to fit into the HTTP model. But we'll talk about how we overcome some of those challenges later.
So what is exactly is a cloud service, that a mobile device might talk to, and how do we differentiate and understand, how these services differ from the typical applications. That we're used to writing. So, let's take a look at an example and hopefully it'll help to clarify and better understand what a cloud service is, and what the scope and what are the challenges that we're going to face, when building these services.
So let's assume we're writing a Java application. And what that java application allows us to do, is we can capture a video and then we can run a command line utility that will be our application. And it will go in save the video, on the underline file system. And not only will be going and save the video in the underlying file system, but it will also take that video and it will save it to a database. So, that we have a record of all of the videos, that we've entered into our system.
So, this is our service in this case or application. That we're going to be building. And we'll assume that there's nothing special about this, it's just a Java application. Well, if we're going to be running this thing over here from the command line, one of the things that we're probably going to want to do, if we're writing this in Java is we're goig to have a main method. So, we might have a public, static, void, main that takes some arguments. And we could go out and spell out what those are. And then in that main method. We might go and do things like you know, look for the flags that were passed on the command line.
So, we can look for flags. We can look for the file that they want to add the video. So, look for the video path, and we can do a whole bunch of other stuff. But the key would be, we've got this main method, which is part of this application and every time from the command line they invoke our application. They're going to be passing commands from the command line into our application, so what we have is a stream of commands that are being passed into our application. So, every time the user goes and invokes this thing from the command line, they're basically sending a different command to it. And the tax that they enter in the command line is then being passed to our public static void main method, where we can start up our application, take action based on the data that they passed us, then going store something in a database, or do something else.
We might also want to issue commands to our application. That have it go and query the information we've already stored, or be processed based on the information we've already set the application. So one of the, the things we might have to do then, is provide feedback to the user that's sending the commands to the application. So we might have something in our main method that's printing out feedback. Using System.out.printline back to the user, so that the user can see the results of the commands that they're issuing. Or see information that comes out of the database that the user is querying. So, not only do we have a situation, where we are sending commands and asking. The application to go and store data, but we also have situations where we need to, based on those commands, go and provide feedback to the user, about the success or failure of those commands and any data associated with them.
So, for example, if the user issues a query to see all of the videos created. In a certain time period we'll probably want to print out the query back to the command line. Similarly if the user issues a query that's malformed. We would probably expect the application to go in print on the command line an error message. Stating what the user did wrong, and helping them to figure out how to formulate that command correctly and send it.
Where if the application went and processed the command, and it had a bug in the program and it crashed or we would expect to get some feedback telling us that the application crashed. So what we'll see is this basic architecture of commands being sent to an application processing data in some format either storing it or performing some analysis on it, and then providing feedback to the user based on the success or failure of those commands, and in the results of the execution of those commands.
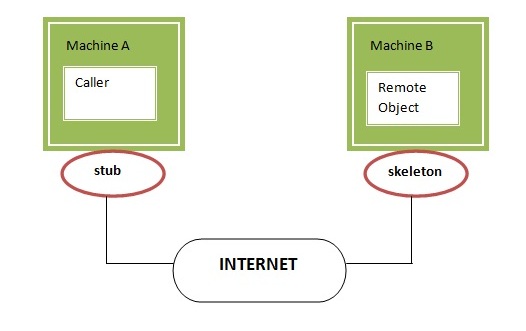
The big difference is when we go into the cloud services model, what we're going to have is, the case where we're sending the commands to the application from a mobile device, that's not sitting on the same app, the same host as that application. So this mobile device is going to be sending this command remotely over the internet. To this application and this application's going to be living in the cloud and receiving those commands, processing data through some data store, saving the information somewhere that's being sent to it, and having to remotely send back to the mobile device, the results of those commands. So, we have this remote interactions that's based on commands being issued to the application and results coming back, that we're going to be working with.
We're going to be sending data from the mobile device, which is the client, to the application. It's going to process that information. And in this case, the application is going to be a server. And it's going to be living in the cloud and then it's going to send the results back to the mobile device, so that it can know what happened. So it may be sending back results that say here's the result of running your command. It may send results back that say you know, did not formulate your command correctly. Or it may be sending results back saying the server had a problem.
Here's what the problem was and it crashed. And that's the architecture that we're going to be building through this class. Is this remote distributed architecture where mobile clients, your mobile devices on Android, are sending commands over the internet, to a service or a server that's living in the cloud. And they're being processed and then results are being sent back to the mobile client. And one of the key questions that we have to answer and address is, how do we get these commands from the mobile device to the server and communicate the results back? What are the requirements and rules for that communication with they server that's remote? How do we ensure that it's reliable? How do we ensure that it's orderly, and done in a way that the server can understand and process commands for us?